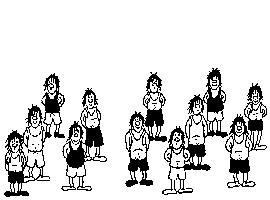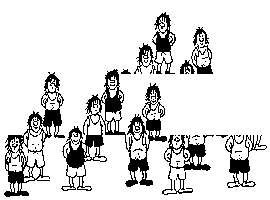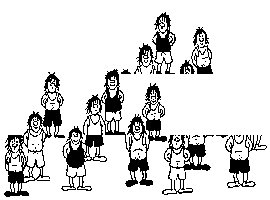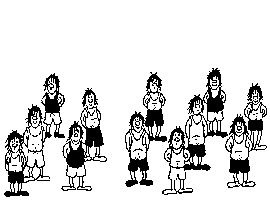
There are 2 configurations. The one where there are 12 people, and the one where there are 13 people. The one where there are 12 people is the "normal" image and the one where there are 13 people is the "modified" image.
In the normal image, each person has a "top" and a "bottom". For each of the 12 people, the amount of pixels for the person on bottom and top are as follows:
| PERSON | BOTTOM | TOP |
|---|---|---|
| 1 | 61 | 5 |
| 2 | 47 | 31 |
| 3 | 2 | 62 |
| 4 | 55 | 14 |
| 5 | 26 | 47 |
| 6 | 51 | 24 |
| 7 | 6 | 63 |
| 8 | 59 | 9 |
| 9 | 35 | 41 |
| 10 | 2 | 67 |
| 11 | 52 | 21 |
| 12 | 16 | 52 |
Now, the images are rearranged as follows to form 13 people:
(NPERSON is the new number of the new person, BOTTOM is the PERSON number whose bottom is taken, TOP is the PERSON number whose top is taken)
| NPERSON | BOTTOM | TOP |
|---|---|---|
| 1 | 1 | none |
| 2 | 2 | 6 |
| 3 | 3 | 7 |
| 4 | 4 | 8 |
| 5 | 5 | 9 |
| 6 | none | 10 |
| 7 | 6 | 11 |
| 8 | 7 | 12 |
| 9 | 8 | 1 |
| 10 | 9 | 2 |
| 11 | 10 | 3 |
| 12 | 11 | 4 |
| 13 | 12 | 5 |
As you can see, the bottom of 1 is used to form a whole person (since the top of that person is an insignificant graphic) and the top of 10 is used to form a whole person (since the bottom of that person is an insignificant graphic). The left-over bottom and top are matched up to the person who has the next least significant bottom or top.
Volume is conserved because the people in the 13-people configuration are much shorter. This is not noticed because the drawings are ugly anyhow.
It would be a lot simpler to understand if the people were sorted from "most bottom pixels and least top pixels" to "least bottom pixels and most top pixels". In this case, instead of a complicated two areas swapping, you'd just shift the top part to the right, which would take off the top 5% off of the leftmost guy, and the top 95% off of the rightmost guy. That extra 95% of the rightmost guy will look like his own guy (and the leftmost guy still looks like a guy).